
Introduction: The Hidden Intelligence Powering Your Digital World
Every time you scroll through personalized product recommendations on an e-commerce site, receive a spam filter that somehow knows which emails are junk, or watch a streaming service suggest your next favorite show, you’re experiencing the power of machine learning in action. Yet, behind these seamless digital experiences lies a sophisticated ecosystem of algorithms working tirelessly to learn from data, identify patterns, and make intelligent predictions. Machine learning has transformed from a niche academic field into the backbone of modern technology, with the global market projected to surge from $47.99 billion in 2025 to an astounding $309.68 billion by 2032 . Understanding how machine learning algorithms work is no longer just for data scientists and engineers; it’s becoming essential knowledge for anyone navigating our increasingly AI-driven world. This comprehensive guide will demystify the core concepts, explore the major types of algorithms, and reveal how these powerful tools are reshaping industries and solving real-world problems.
What Are Machine Learning Algorithms?
At its core, a machine learning algorithm is fundamentally different from traditional computer programs. Rather than following explicit step-by-step instructions, a machine learning algorithm is like a recipe that allows computers to learn and make predictions directly from data. Instead of explicitly telling a computer what to do, we provide it with large amounts of data and let it discover patterns, relationships, and insights on its own .
Think of it this way: a traditional program might have thousands of lines of code specifying exactly what to do in every scenario. A machine learning algorithm, by contrast, learns from examples. If you want to build a system that recognizes cats in photos, you don’t write rules for “if the image has pointy ears, it’s a cat.” Instead, you feed the algorithm thousands of cat and non-cat images, and it learns the distinguishing features on its own. This fundamental shift from explicit programming to learning-based approaches is what makes machine learning so powerful and flexible.
The Five Major Types of Machine Learning
Machine learning encompasses several distinct approaches, each suited to different problems and data scenarios. Understanding these categories is crucial for grasping how different algorithms work and when to apply them.
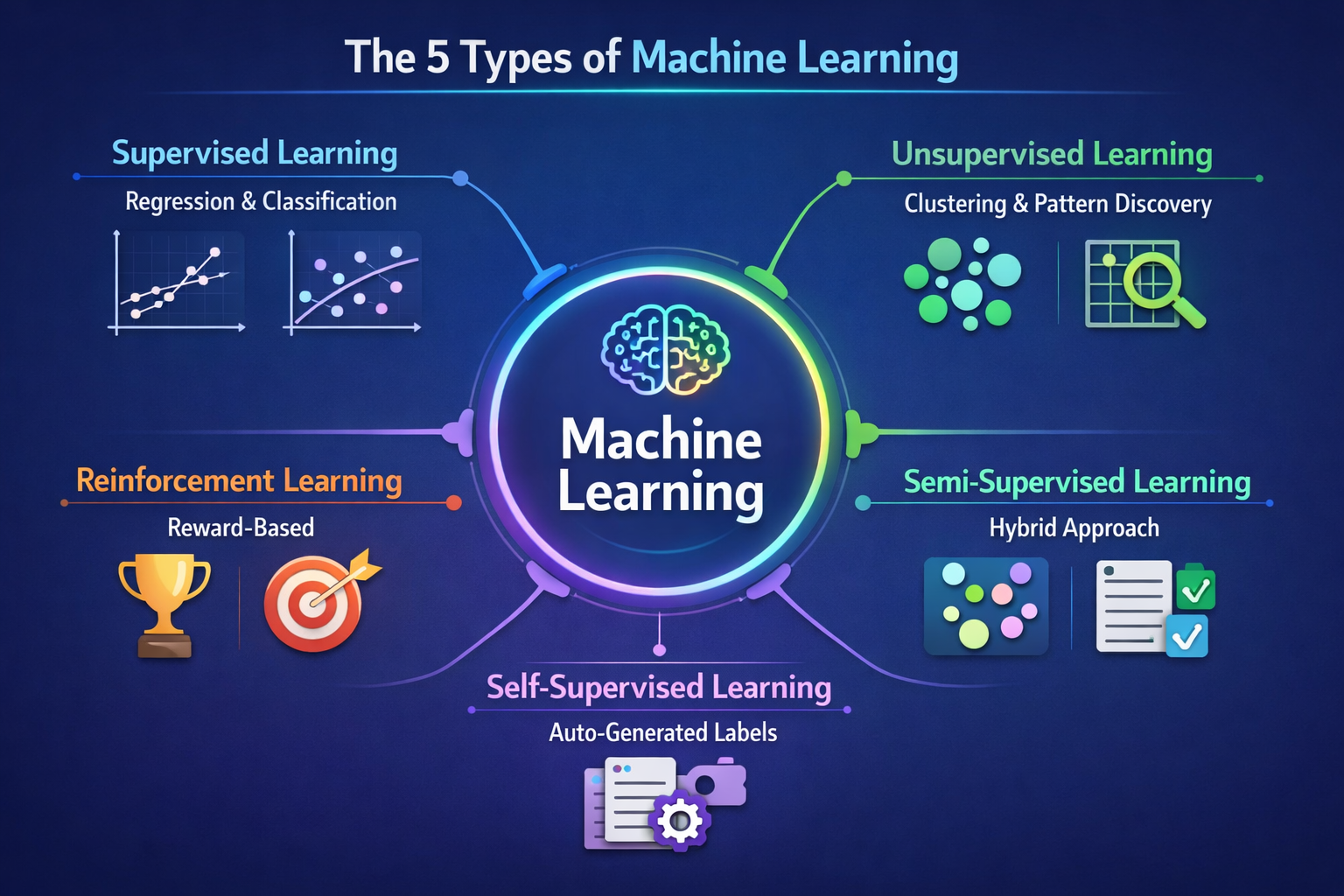
1. Supervised Learning: Learning from Labeled Examples
Supervised learning is the most common type of machine learning used in practice today. In supervised learning, the algorithm is trained on a labeled dataset, meaning each input example comes with a known correct answer or output . For instance, if data scientists were building a model for tornado forecasting, the input variables might include date, location, temperature, and wind flow patterns, while the output would be the actual tornado activity recorded for those days .
Supervised learning splits into two primary subcategories. Regression algorithms predict continuous numerical values, such as housing prices or temperature forecasts. Classification algorithms, conversely, predict categorical outcomes, such as whether an email is spam or legitimate. This distinction is fundamental: regression answers “how much?” while classification answers “which category?” .
2. Unsupervised Learning: Discovering Hidden Patterns
Unsupervised learning tackles a different challenge: finding meaningful patterns in data without any labeled examples to guide the process. These algorithms work with unlabeled datasets, drawing inferences and facilitating exploratory data analysis . The most common unsupervised learning method is cluster analysis, which uses clustering algorithms to categorize data points according to their similarity. For example, an e-commerce company might use unsupervised machine learning to segment customers into distinct groups based on purchasing behavior, enabling more targeted marketing strategies .
3. Self-Supervised Learning: Generating Your Own Labels
Self-supervised learning represents a more recent innovation in machine learning, enabling models to train themselves on unlabeled data by automatically generating labels. These algorithms learn one part of the input from another part, transforming unsupervised problems into supervised ones . This approach is particularly valuable for computer vision and natural language processing, where the volume of labeled training data needed can be prohibitively large.
4. Reinforcement Learning: Learning Through Rewards and Penalties
Reinforcement learning, also called reinforcement learning from human feedback (RLHF), employs a fundamentally different strategy. Rather than learning from labeled examples, an agent learns by interacting with an environment and receiving rewards or penalties based on its actions . This approach is common in video game development and is frequently used to teach robots how to replicate human tasks. The agent learns the best strategies through repetition and feedback, gradually improving its performance.
5. Semi-Supervised Learning: The Best of Both Worlds
Semi-supervised learning combines elements of supervised and unsupervised approaches, training on a small labeled dataset alongside a large unlabeled dataset . The labeled data guides the learning process for the larger body of unlabeled data. A semi-supervised learning model might use unsupervised learning to identify data clusters and then use supervised learning to label those clusters. Generative Adversarial Networks (GANs), which generate unlabeled data by training two neural networks against each other, exemplify this hybrid approach .
Essential Machine Learning Algorithms You Should Know
Within these five categories, numerous specific algorithms have proven their value across countless applications. Here are some of the most important and widely-used machine learning algorithms that form the foundation of modern data science.
Linear Regression: Predicting Continuous Values
Linear regression is a supervised machine learning technique used for predicting and forecasting values that fall within a continuous range, such as sales numbers or housing prices . Derived from statistics, linear regression establishes a relationship between an input variable (X) and an output variable (Y) that can be represented by a straight line. The algorithm finds the line that best fits the data points, creating a predictive model that can estimate output values for new inputs .
Logistic Regression: Binary Classification Made Simple
Despite its name, logistic regression is primarily used for classification rather than prediction. This supervised learning algorithm is particularly valuable for binary classification tasks—determining whether an input belongs to one class or another . For instance, it can determine whether an email is spam or legitimate, or whether a medical image indicates the presence of disease. Logistic regression predicts the probability that an input belongs to a specific class and uses a threshold to make the final classification decision .
Decision Trees: Interpretable and Intuitive
A decision tree resembles a flowchart, starting with a root node that asks a specific question about the data . Based on the answer, the data is directed down different branches to subsequent nodes, which ask further questions. This process continues until reaching a leaf node where the final classification or prediction is made . Decision trees are popular because they handle complex datasets with ease and their structure makes the decision-making process straightforward to understand and interpret.
Random Forest: Ensemble Power
A random forest algorithm combines the predictions from multiple decision trees to make more accurate predictions than any single tree could achieve . Instead of relying on one decision tree, a random forest trains numerous decision trees (sometimes hundreds or thousands) using different random samples from the training data. Each tree produces a prediction, and the random forest selects the most common prediction as the final result . This ensemble approach addresses overfitting, a common problem where a single decision tree becomes too closely aligned with its training data.
K-Nearest Neighbor (KNN): Proximity-Based Classification
K-nearest neighbor is a supervised learning algorithm that classifies outputs based on proximity to other data points . When classifying a new data point, KNN examines its K nearest neighbors in the dataset. If most of these neighbors belong to a particular class, the new point is assigned to that class . Despite its simplicity, KNN is remarkably effective for many classification tasks and serves as an excellent introduction to machine learning algorithms.
K-Means: Unsupervised Clustering
K-means is an unsupervised algorithm commonly used for clustering and pattern recognition tasks . It groups data points based on their proximity to one another, with each cluster defined by a centroid or center point. K-means is particularly useful for large datasets, though it can struggle with outliers . Applications include customer segmentation, image compression, and anomaly detection.
Support Vector Machine (SVM): Powerful Classification
A support vector machine is a supervised learning algorithm that creates a decision boundary called a “hyperplane” to separate different classes . SVMs are particularly valued because they work well even with small amounts of data and can handle complex, non-linear classification problems through kernel methods .
Types of Machine Learning Compared
| Type | Data Requirements | Best For | Key Characteristics | Examples |
| Supervised Learning | Labeled data with known outputs | Prediction and classification | Requires labeled training data; high accuracy; well-defined targets | Linear regression, logistic regression, decision trees, SVM |
| Unsupervised Learning | Unlabeled data | Pattern discovery and clustering | No labeled data needed; explores data structure; finds hidden patterns | K-means, hierarchical clustering, PCA, Apriori |
| Self-Supervised Learning | Unlabeled data with auto-generated labels | Computer vision and NLP | Generates labels automatically; reduces annotation burden; scalable | Contrastive learning, masked language models |
| Reinforcement Learning | Environment interaction with rewards | Decision-making and optimization | Learns through trial and error; reward-based feedback; agent-based | Game AI, robotics, autonomous systems |
| Semi-Supervised Learning | Mix of labeled and unlabeled data | Limited labeled data scenarios | Combines supervised and unsupervised approaches; cost-effective | GANs, label propagation, co-training |
Key Machine Learning Algorithms Explained
| Algorithm | Type | Use Case | Strengths | Limitations |
| Linear Regression | Supervised | Predicting continuous values (sales, prices, temperature) | Simple, interpretable, fast, works well with linear relationships | Assumes linear relationship; poor with non-linear data |
| Logistic Regression | Supervised | Binary classification (spam detection, disease diagnosis) | Fast, interpretable, probabilistic output, works with small datasets | Limited to binary or multi-class; assumes linear decision boundary |
| Decision Tree | Supervised | Classification and regression with interpretability needs | Highly interpretable, handles non-linear relationships, no scaling needed | Prone to overfitting, unstable with small data changes |
| Random Forest | Supervised | Robust classification and regression | Reduces overfitting, handles non-linear relationships, feature importance | Less interpretable, computationally expensive, memory intensive |
| K-Nearest Neighbor (KNN) | Supervised | Classification and regression with small datasets | Simple, no training phase, works with non-linear data | Slow prediction, sensitive to feature scaling, poor with high dimensions |
| Naive Bayes | Supervised | Text classification, spam filtering, sentiment analysis | Fast, works well with small datasets, probabilistic | Assumes feature independence (often violated in practice) |
| Support Vector Machine (SVM) | Supervised | Complex classification, high-dimensional data | Effective in high dimensions, memory efficient, versatile kernels | Slow with large datasets, requires feature scaling, hard to interpret |
| K-Means | Unsupervised | Customer segmentation, image compression, clustering | Fast, scalable, simple to implement, works well with spherical clusters | Requires specifying K, sensitive to outliers, may converge to local minima |
| Hierarchical Clustering | Unsupervised | Taxonomy creation, exploratory analysis | No need to specify K, produces dendrograms, hierarchical structure | Computationally expensive, irreversible decisions |
| Neural Networks | Supervised/Deep Learning | Complex pattern recognition, image/speech recognition, NLP | Highly flexible, can learn complex non-linear relationships | Requires large datasets, computationally expensive, less interpretable |
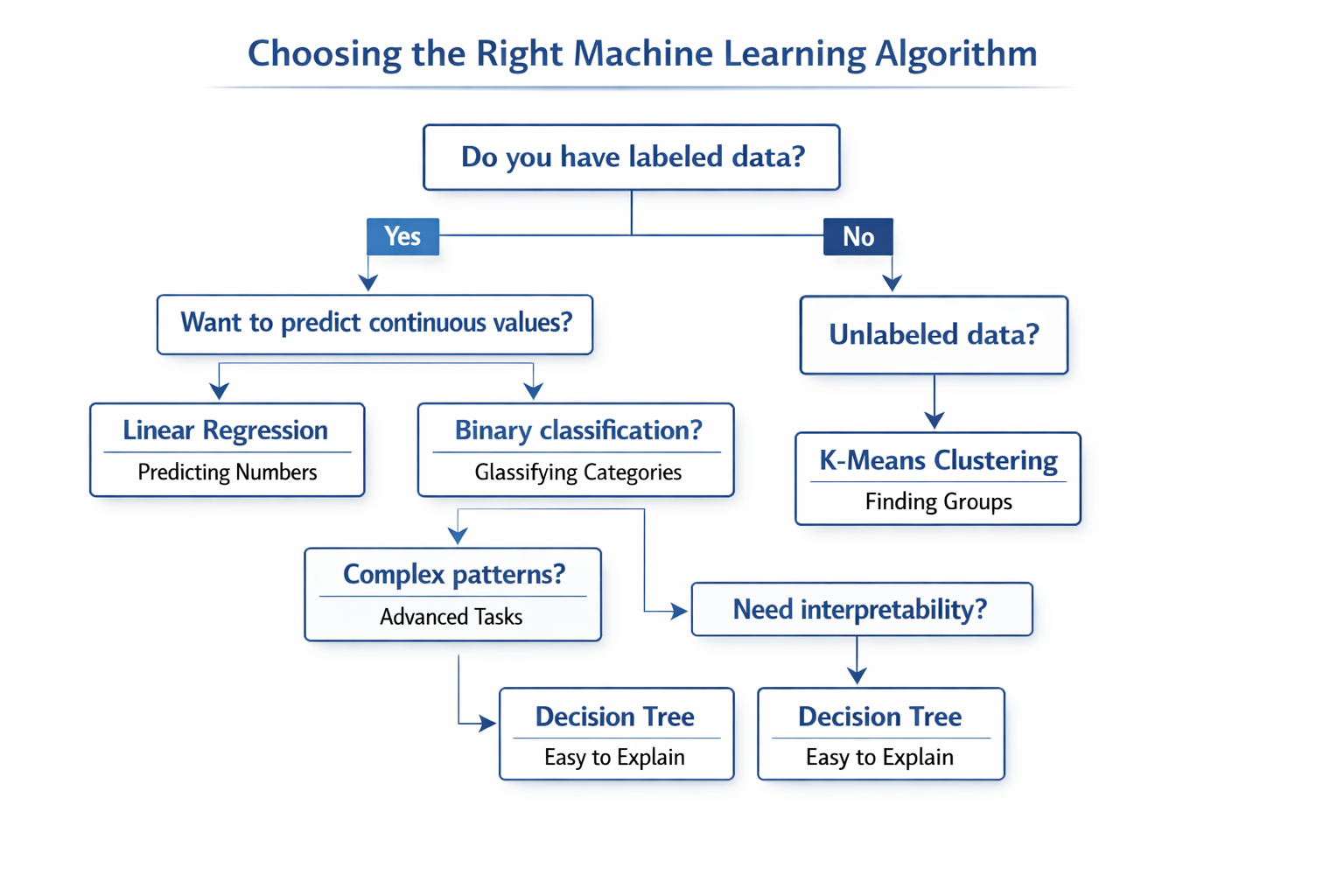
Choosing the Right Algorithm
Selecting the appropriate machine learning algorithm for your problem is as much art as science. The decision depends on several factors including the nature of your data, the size of your dataset, the specific problem you’re solving, and your interpretability requirements.
Machine Learning Algorithms in Action: Real-World Applications
The theoretical elegance of machine learning algorithms becomes truly powerful when applied to real-world problems. Healthcare providers use supervised learning algorithms for medical diagnosis and image analysis, achieving diagnostic accuracy that rivals or exceeds human specialists . Financial institutions deploy machine learning algorithms for fraud detection and risk assessment, protecting both institutions and consumers . E-commerce platforms use unsupervised learning for customer segmentation and recommendation systems, driving revenue through personalized experiences .
In autonomous vehicles, multiple machine learning algorithms work in concert—computer vision algorithms process camera feeds, reinforcement learning algorithms optimize driving decisions, and prediction algorithms anticipate other road users’ behavior. In natural language processing, transformer-based neural networks (a type of deep learning algorithm) power language models that can translate between languages, answer questions, and even generate human-like text.
The Future of Machine Learning Algorithms
As we move into 2026 and beyond, the landscape of machine learning algorithms continues to evolve rapidly. The trend toward “AI factories” suggests that organizations will increasingly build comprehensive infrastructure around machine learning, moving beyond isolated projects to systematic, enterprise-wide adoption . Explainable AI is gaining prominence, addressing the “black box” problem where even developers cannot fully understand why an algorithm made a particular decision. Multimodal AI, which processes multiple types of data simultaneously (text, images, audio), is opening new possibilities for machine learning algorithms .
The convergence of machine learning algorithms with other emerging technologies promises even more transformative applications. Quantum computing combined with machine learning algorithms could solve optimization problems currently intractable for classical computers. Edge computing brings machine learning algorithms directly to devices, enabling real-time processing without cloud connectivity.
Conclusion: Embracing the Age of Intelligent Algorithms
Machine learning algorithms have moved from academic curiosity to essential infrastructure in our digital world. From the simple elegance of linear regression to the sophisticated power of deep neural networks, these algorithms represent humanity’s attempt to imbue machines with the ability to learn, adapt, and make intelligent decisions. Understanding how machine learning algorithms work—their strengths, limitations, and appropriate use cases—is increasingly valuable for professionals across all industries.
The journey from data to insight, from observation to prediction, and from problem to solution increasingly flows through machine learning algorithms. Whether you’re building recommendation systems, detecting fraud, diagnosing diseases, or optimizing operations, the principles and algorithms discussed in this guide form the foundation. As these technologies continue to advance and become more accessible, the ability to understand and work with machine learning algorithms will become as fundamental as computer literacy is today.
Are you curious about diving deeper into machine learning algorithms? Consider exploring hands-on courses that let you build models yourself, or experiment with open-source libraries like scikit-learn and TensorFlow. What machine learning applications excite you most? Share your thoughts in the comments below, and let’s discuss how these powerful algorithms are shaping your industry and future!
References
[1] Coursera. (2025, December 4). 10 Machine Learning Algorithms to Know in 2026.
[2] IBM. (2025). Five machine learning types to know.
Want to read more about Ai
Complete Guide to AI Fundamentals: Unraveling AI History & AI Applications

